Navigating complex Puppet setups - part 2
December 23, 2014
puppet
In the previous part of this series of blogs I showed how, and why, complex Puppet setups come into existence, and some general guidelines to keep yourself from getting lost. In this part I will give you a pratical example of how module classification works, show you how you can manage your upstream code, and show you how to set up the basics for a local development environment.
Module classification
As I explained in the previous part, classifying modules and setting rules for inheritance are key parts part in preventing ‘spaghetti’. Let’s take another look at the example I used:
- generic level: usually upstream modules.
- company level: defining a company standard for certain functionality.
- project level: implementing the company level module but with certain project-specific settings.
- role level: creating a role which consists of a set combination of modules.
We are specifying 4 tiers, from most generic to most specific. Seems simple, right? But there is a little more to it.
Adapting to your organization
The 4 tiers I introduced are not just meant to label a Puppet module as ‘generic’, ‘a little less generic’ or ‘really specific’. A different tier can also mean different ownership, different review process, different change windows, etcetera. Let me give you some examples of how your organization could affect your Puppet codebase:
- Change window: changes to company-level code are deployed only once a day, at 10pm. Changes to project-level code are deployed once every hour.
- Code ownership: generic and company-level code is owned by the Core Operations team, project-level code is owned by the team working on the project.
- Review process: changes to project-level code only require approval of 1 person, changes to company-level code require approval of 3 people.
- Backwards compatibility: rules for changing default behaviour of a project-level module are made by the project team. Changing behaviour of company-level modules requires multiple steps:
- introducing the new functionality (if any).
- making the behaviour you want to change configurable, but not changing default behaviour yet.
- informing the teams that are implementing your module about the impending change in default behaviour, giving them 2 months to adapt and test their implementation.
- changing default behaviour on testing/staging environment.
- changing default behaviour on production.
As you can see, module classification is not just about functionality; it is also very much about organization. This also means that my example may not apply to your company. You may end up with more or different tiers.
Module inheritance
In the previous part, I used the example below:
Any module can only implement or inherit modules that are less specific than the module itself.
So how does that work? Let’s look at the image below:
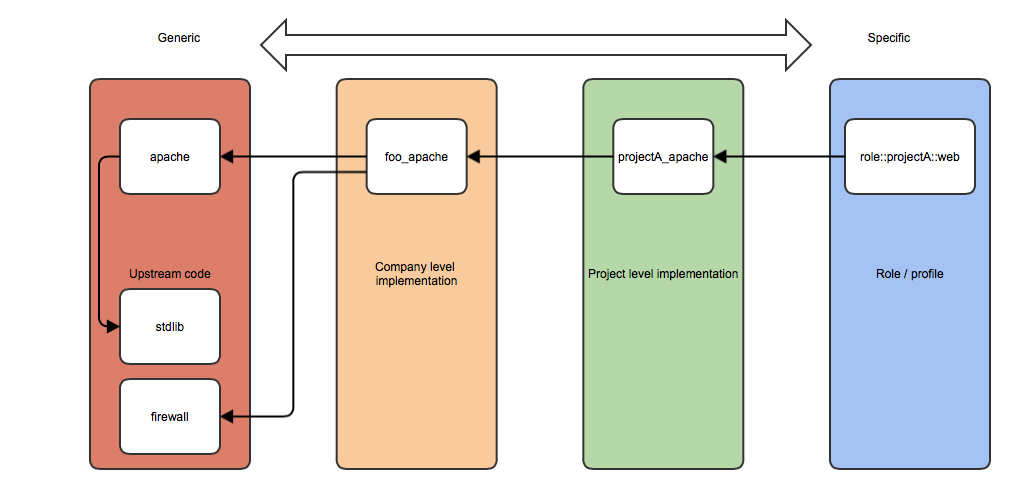
At the ‘generic level’ we have a few upstream Puppet modules that we downloaded from the Puppet Forge: apache, stdlib and firewall. The apache module uses functionality from the stdlib module. Since there is no ‘less specific’ tier available, this so-called vertical include is allowed, but only at this level.
At the ‘company level’ we created a module called foo_apache that implements the generic-level apache module using default parameters for our company, and sets limits on what settings can and cannot be changed by project-level modules. It also adds the required firewall rules.
At the ‘project level’ we created a module called projectA_apache that sets up Apache according to our company standards, but perhaps uses different document root paths or enables a module that is disabled by default. This module may be just a few lines of code:
class projectA_apache {
class { 'foo_apache':
enable_mods => [ 'mod_rewrite', 'mod_ldap_auth' ],
}
}
At the ‘role level’, we created a module called role::projectA::web that sets up a webserver for project A. It implements the projectA_apache module, sets up the appropriate virtual hosts, and deploys the SSL certificates.
Do not create duplicate functionality!
A common pitfall when working with multiple project teams which all use similar functionality is that some team decides to ’re-invent the wheel', and after a while you will end up with several different modules to install Java, setup MySQL or manage SSL certificates. Even worse, some teams may decide to copy a company-level module because they fear changes to the company-level module will affect their project.
A general rule of thumb is to never create duplicate functionality. If an available module lacks functionality needed by a project team, it should be added, so everyone can benefit.
The issue of duplicate functionality usually occurs in larger organizations with isolated project teams and/or lack of communication between teams. Using a central issue tracker and scheduling regular meetings to discuss issues with various teams is usually a good idea.
Upstream modules: use the Forge
As I said earlier: it’s a bad idea to create duplicate functionality. This also applies to adding new functionality to your codebase. In a lot of cases, there may be one or more ready-to-use modules available on the Puppet Forge.
While quality of the modules on the Forge varies, the amount of downloads usually is a pretty good indicator of its general quality. Also, Puppetlabs have recently added a rating system to the Forge.
Use specific versions
So now you’ve found a nice module on the Forge. You’ve installed it, tested it, and everything works. Great! Now is a good time to write down which specific version of the module you are using, because you’re going to need it later.
Why should I write down a version number? The module works. What’s the problem!?
The module works indeed. This specific version of it. There is no guarantee a newer version won’t break your Puppet setup. Default behaviour might change, new parameters may be added, old ones removed or renamed. There may be an issue with the module that the maintainer doesn’t know about yet. And all of a sudden, you cannot log on to any of your servers, because the pam_ldap module broke.
By using specific versions, your upstream modules will always be exactly the same. So write down that version number!
Managing your upstream modules
You may be familiar with the puppet module install command to quickly install a module you found on the Forge. While this is a perfectly good way to add a module to your development setup, using it in production is a bad idea. When you install modules using puppet module install, you are installing the latest version of a module. From the internet. By hand. On a production system.
Managing for pros: R10K and Puppetfile
So we’ve created a list of the names and versions of the upstream modules we want to use in our setup. It looks somewhat like this:
puppetlabs-firewall 1.3.0
puppetlabs-mysql 3.1.0
puppetlabs-stdlib 4.5.0
...
We could go ahead and install those modules by using a little script that reads this file line by line, and does something like:
puppet module install <first field> -v <second field>
But that would break if I wanted to update a module to a newer version, and it wouldn’t get rid of modules I now longer need. So we need something a bit more advanced.
Meet: the Puppetfile. A Puppetfile is a (slightly) more advanced version of our list of names and versions. It looks somewhat like this:
mod 'puppetlabs/firewall', '1.0.2'
mod 'stahnma/puppetlabs_yum', '0.1.4'
mod 'stahnma/epel', '0.0.6'
mod 'puppetlabs/apt', '1.4.2'
mod 'puppetlabs/ntp', '3.0.3'
mod 'saz/ssh', '2.3.2'
mod 'saz/sudo', '3.0.3'
mod 'saz/timezone', '3.0.1'
mod 'saz/rsyslog', '2.3.0'
...
mod 'yum',
:git => 'https://github.com/CERIT-SC/puppet-yum.git',
:ref => 'adf02da7e6ba597ca55c7f92cc76248ad302754e'
So, it’s basically the same list of module names and version numbers, but it also supports Git, so if you have found some module on Github that isn’t available on the Forge, you can still use it.
To put our Puppetfile to use, we can use R10K. I will explain more about installing the various tools later; for now, we will stick to just using R10K. There are three things R10K kan do with a Puppetfile: check, install and purge.
- Check: By running
r10k puppetfile checkyou are instructing R10K to read./Puppetfileand check the syntax of the file. - Install: When you run
r10k puppetfile install, R10K will read./Puppetfileand install all modules listed in the file into./modules/. - Purge: If you run
r10k puppetfile purge, R10K will remove all modules from./modules/that are not in the Puppetfile.
Let’s connect the dots. We have our Puppetfile, and we have R10K to do the heavy lifting for us. Let’s write a simple script that checks our Puppetfile, installs the modules we need, and gets rid of the modules we don’t need.
#!/bin/bash
GITTOPLEVEL="$(git rev-parse --show-toplevel)"
set -e
cd ${GITTOPLEVEL}
for fileaction in check purge install; do
echo "[Puppetfile] ${fileaction}"
r10k -v INFO puppetfile ${fileaction}
done
exit 0
That’s it. We can now manage all of our upstream modules with just two text files.
Considerations for production setups
It’s not unusual that internet access is restricted (or even prohibited) for production systems. It’s also not unusual for online services (like the Puppet Forge or Github) to experience a little hiccup every now and then. So what do you do when you cannot access the internet from your Puppet master or you simply don’t want to depend on Github/Forge working properly?
One of the possible solutions is running R10K on a separate machine, and creating a package or tarball you can deploy on your Puppet master. You can still use R10K in you development/testing setups.
Local development
Writing any kind of code usually requires at least three ingredients:
- An editor/IDE to write the code.
- An interpreter/compiler/linter to compile or verify the code.
- A testing environment to run the code and to safely ‘break everything’.
NOTE: I do not have any experience with development on Windows systems. I will focus on Mac and Linux in this blog.
Puppet editor
There are tons of pretty great editors and IDEs on the market nowadays, and it’s hard to pick just one as a favorite as so much of it comes down to personal preference. To give you an idea, here’s an (incomplete) list of editors used to write Puppet code at Avisi:
All of these editors will get the job done. Just pick the one you are most comfortable with. I personally use SublimeText 2.
Puppet interpreter & tools
You need a few Ruby gems installed on your system to make the most of your development setup. You can easily install them by running:
sudo gem install puppet puppet-lint r10k
Testing environment: Vagrant
For our testing environment we will use Vagrant and Oracle Virtualbox. Vagrant provides an easy way to create portable development setups.
You can install Vagrant by downloading the appropriate package. Also, don’t forget to install Virtualbox, and reboot your machine. Once you have installed Vagrant you can check if everything is in order, by running:
$ vagrant global-status
id name provider state directory
--------------------------------------------------------------------
There are no active Vagrant environments on this computer! Or,
you haven't destroyed and recreated Vagrant environments that were
started with an older version of Vagrant.
If everything works properly, let’s install some plugins. I personally use the vagrant-cachier and vagrant-hosts plugins a lot. Cachier acts as a caching mechanism for package management inside your Vagrant setups (saves some time when repeatedly installing the same packages), and the hosts plugin can update the /etc/hosts files of your VMs in multi-VM setups. Install the plugins by running:
vagrant plugin install vagrant-hosts
and:
vagrant plugin install vagrant-cachier
Running your first Vagrant VM
Let’s fire up our first Vagrant setup, using a single Ubuntu Trusty VM:
vagrant up ubuntu/trusty64 --provider virtualbox
This will download the ubuntu/trusty64 box, create a default Vagrantfile and start a VM based on that box. Downloading of the box may take a few minutes depending on your internet connection, everything else shouldn’t take much more than 30 seconds if your machine has a solid state drive.
Coming soon in part 3
In part 3 of this series I will be covering advanced usage of Vagrant and I will show you how you can create a fully automated Puppet development setup.